TrainTestClassififier Tutorial
Classification means learning labels for entire documents. TrainTestClassifier tasks use text data. For this example we will use sample3.train as the training data and sample3.test as the testing data. These samples are built into the code, so they require no additional setup. To see how to label and load your own data for this task, look at the Labeling and Loading Data Tutorial.
This experiment will train on one set of data and test on another set. The test set is determined either by specifying test Data or by splitting the data. The experiment outputs statistic such as Error rate, standard deviation, and kappa.
To run this type of task start with:
java –Xmx500M edu.cmu.minorthird.ui.TrainTestClassifier
Editing Parameters:
Like all ui tasks, all the parameters for TrainTestClassifier may be specified in either the gui or by the command line. To use the gui, simple type the –gui on the command line. It is also possible to mix and match where the parameters are specified; for example: one can specify two parameters on the command line and use the gui to select the rest. For this reason, the step by step process for this experiment will first explain how to select a parameter value in the gui and then how to set the same parameter on the command line.
To view a list of parameters and their functions run:
% java –Xmx500M edu.cmu.minorthird.ui.TrainTestClassifier –help
OR
% java –Xmx500M edu.cmu.minorthird.ui.TrainTestClassifier –gui
And click on the “Parameters” button next to Help or and click on the “?” button next to each field in the Property Editor to see what it is used for.
If using the gui, click the edit button next to TrainTestClassifier when a window appears to edit the parameters. A Property Editor window will appear

1) There are five bunches of parameters to specify for this experiment. The only required parameters are labelsFilename (-labels) and spanType or spanProp.
1. baseParameters: contains the options for loading the collection of documents.
a) GUI: Enter sample3.train in the labelsFilename textField.
b) Command Line: use the –labels option followed by the repositoryKey or the directory of files to load. In this case specify –labels sample3.train
2. saveParameters: contains one parameter for specifying a file to save the result to. Saving is optional, but useful for using resulting classifier for TestClassifier and ApplyAnnotator experiments.
a) GUI: Type sample3.ann in the saveAs textField
b) Command Line: -saveAs sample3.ann
3. signalParameters: Either spanType or spanProp must be specified as the type to learn. For this experiment we will test spanType fun.
a) GUI: click the “Edit button next to singnalParameters. Select “fun” from the pull down menu next to spanType.
b) Command Line: specify –spanType fun
4. splitterParameters: either a splitter or a testFilename may be specified. In this experiment, set the testFilename to sample3.test. Entering a testFilename will tell minorthird to ignore the splitter and use the test file. To use a splitter, simply do not specify a testFilename and select the appropriate splittler from the pull down menu. The splitter is set to RandomSplitter by default and will run with that if no other splitter is selected.
a) GUI: enter sample3.test next to testFilename
b) Command Line: -test sample3.test
5. trainingParameters: contains parameters for specifying learning options, most importantly the learner used. We will use the default learner, NaiveBayes, for this experiment, but feel free to change the learner for future experiments.
a) GUI: Change the learner by selecting a new learner from the pull down menu
b) Command Line: Selecting a different learner (or any other class) on the command line can be tricky. The full class must be specified. To get more information on the class of the learner, look at the javadocs (there is a link to the specific learner class in the javadocs in the help link next to learner.) Most learner may be specified on the command line using this format: -learner “new Recommended.LEARNER_NAME()”. Check javadocs for possible initialization parameters.
2) Feel free to try changing any of the other parameters including the ones in advanced options.
a. GUI: Click on the help buttons to get a feeling for what each parameter does and how changing it may affect your results. Once all the parameters are set, click the “OK” button on the PropertyEditor.
b. Command Line: Add other parameters to the command line (use –help option to see other parameter options) If there is an option that can be set in the gui, but there is no specific parameter for setting it in the help parameter definition, the –other option may be used. To see how to use this option, look at the Command Line Other Option Tutorial.htm
3) GUI: Once finished editing parameters, save parameter modification by clicking the “OK” button on the Property Editor.
Show Labeled Data:
2) GUI: Press the Show Labels button if you would like to view the input data for the classification task.
3) Command Line: add –showLabels to command line
Getting and Interpreting Results:
1) Command Line: specify –showResult (this is for seeing the graphical result, if this option is not set, only the output statistics of the task will be seen)
1) Press Start Task under execution controls to run the experiment. The task will vary in the amount of time it takes depending on the size of the data set and what learner and splittler you choose. When the task is finished, the error rates will appear in the Error messages and output text area along with the total time it takes to run the experiment.
2) Once the experiment is completed, click the View Results Button in the Execution Controls section to see detailed results in the gui or the window will automatically appear if the –showResult option was chosen on the command line. The Test Partition tab shows the testing examples in the top left, the classifier in the top right, the selected test example’s features, source, and subpopulation in the bottom left, and the explanation for the classification of the selected test example in the bottom right (expand the tree to see the details of the explanation.)

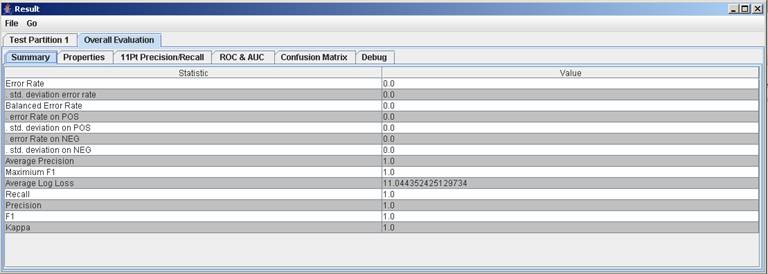
3) Click on the Overall Evaluation tab at the top and the Summary tab below that to view your results. The summary tab shows you the results that were printed in the output window when you ran the experiment (it shows you the numbers like error rate and F1.) The Precision/Recall tab show you the graph of Recall vs. Precision graph for this experiment. The Confusion Matrix tab shows you how many things the classifier predicted as positive that are positive and how many that it predicted as positive that are negative and visa versa.
1. 
4) Press the “Clear Window” button to clear all output from the output and error messages window.