TrainExtractor Tutorial
Extraction means extracting types within documents (such as names or places.) TrainTestExtractor tasks use text data. For this example we will use sample1.train as the training data. This sample is built into the code, so it requires no additional setup. To see how to label and load your own data for this task, look at the Labeling and Loading Data Tutorial.
This experiment will train on a training set and output an extractor, which can be used to test another dataset or applied on an unlabeled dataset to added labels (such as extracted_name.)
Using the gui:
1) To run this type of task using the gui type:
java –Xmx500M edu.cmu.minorthird.ui.TrainExtractor –gui
A window will appear. The view and change the parameters of the experiment press the Edit Button located next to TrainExtractor. A PropertyEditor will appear:

2) To view what each parameter does and/or how to set it, click the “?” button next to each field. The parameters that must be entered for the experiment to run are baseParameters (-labels) and signalParameters (-spanType or –spanProp) All other parameters have default or are not needed for the result. There are 4 bunches of parameters that can be modified for running a TrainExtractor experiment:
1. Options for how minorthird learns from the training data are in additionalParameters. These options all have defaults, so do not need to be explicated stated for the experiment to run. Most importantly the learner can be changed by selected a learner from the pull down menu and edited by pressing the “Edit” button next to learner. To view the javadoc documentation for the currently selected learner, press the “?” button for a link to javadocs. The output parameter specifies how minorthird labels extracted types. By default it is set to prediction, but it is useful to change this to something more informative such as predicted_trueName.
2. First training data for the experiment must be entered by specifying a labelsFilename. Since the samples are built into the code, sample1.train can simply be typed into the TextField under labelsFilename to load the data. Note: data from a directory can be loaded by using the browse button.
3. To save the results from the experiment, enter a file to which to write the results in the sasveAs text field. Note: this is optional, yet necessary in order to use the saved extractor in the future.
4. Once labelsFilename is specified, click the “Edit” button next to signalParamters. IMPORTANT: labelsFilename must be specified BEFORE clicking “Edit”. Another Property Editor will appear.
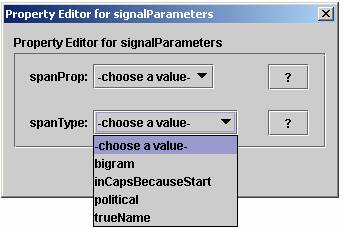
Select the trueName from the pull down menu. Then press the “OK” button to close the PropertyEditor for signalParameters
3) Feel free to try changing any of the other parameters including the ones in advanced options. Click on the help buttons to get a feeling for what each parameter does and how changing it may affect your results. Once all the parameters are set, click the “OK” button on the PropertyEditor.
4) Press the Show Labels button if you would like to view the input data for the extraction task. This will pop up the same TextBaseViewer that you would see if you ran ViewLabels on the train data.
5) Now press Start Task under execution controls. The task will vary in the amount of time it takes depending on the size of the data set and what learner was chosen, but extraction tasks usually take a minute or two. When the task is finished, the error rates will appear in the Error messages and output text area along with the total time it takes to run the experiment.
6) When the experiment has finished running, click the “View Results” button to view the extractor.

The features in the extractor may be sorted by name, weight (seen on the left), or absolute weight or be viewed in a tree (as seen on the right) where the root contains the highest value of the leaves below. Features with the largest weights are most highly correlated with have the specified spanType. In this case tokens with charTypePattern capital letter followed by lower case letter is most highly correlated with trueName since it is the feature with the largest weight in the extractor.
7) Press the “Clear Window” button to clear all output from the output and error messages window. This is useful if you would like to run another experiment.
Using the Command Line:
1) To get started using the command line for a classification experiment type:
java –Xmx500M edu.cmu.minorthird.ui.TrainTestExtractor –help
This will list all the command line arguments that you can use.
Note: You can enter as many command line arguments as you like along with the –gui argument. This way you can use the command line to specify the parameters that you would like and use the gui to set any additional parameters or view the results
2) Show options: specifying these options allow one to pop up informative windows from the command line
a. -showData –interactively show the dataset in a new window
b. –showLabels – view the training data and its labels
c. –showResult – displays the experiment result in a new window (see step 6 in Using the gui)
3) The first thing you probably want to enter on the command line is the data you would like to train or train/test on. To do this type –labels and the repository key of the dataset you would like to use. For this experiment you should type: –labels sample1.train
4) The next necessary parameter to name is either spanProp or spanType. To specify this parameter, type –spanType TYPE. For this dataset TYPE can either be real or spam, so type: -spanType trueName.
5) Other parameters you may want to specify are: the learner (-learner) or whether to save. Use the –help command for descriptions and examples of these parameters. If you are unsure of what learners, use the –gui command so that you can see the list of learners and feature extractor available (under trainingParameters). For this experiment, you can type:
6) -learner “new VPHMMLearner(new CollinsPerceptronLearner(1,5), new Recommended.TokenFE(), new InsideOutsideRedution())”
7) As you can see from this example, the sequenceClassifierLearner, spanFeatureExtractor, and taggingReduction are defined with the learner. If you would like to see the options for these variables, use the –gui command. Once the parameter modification window pops up, click Edit under Parameter Modification and click Edit next to training Parameters. To see what learners are available, scroll through the pull down list next to learner. Once you have chosen a learner, click the Edit button next to learner to choose your sequenceClassifierLearner, spanFeatureExtractor, and taggingReduction. To edit any of these training parameters, press the Edit button next to them.
8) Optional parameters to define are –mixup, -embed, or –output. Use the –help command to learn more about these parameters. –output is set to the default _prediction, so you only need to set this parameter if you would like to the name of the property learned.
9) Specifiying complex parameters on the command line using the –other option:
To specify anything on the command line you can use the -other
option. The way to do this is specify the path name and what it
equals. For example: to set history size:
-other learner.historySize=3
or to change the numberOfEpochs in the SequenceClassifierLearner
-other learner.sequenceClassifierLearner.numberOfEpochs=10
Basically all one has to do is look in the gui and see all the property names,
every time you press the edit button you need to add the property you are
editing to the path. So if you want to edit something in learner you can
specify -other learner.PROPERTY_NAME. Also here is how to specify a class
with the other option:
-other learner.spanFeatureExtractor="ui.Recommended.DocumentFE"
To find the correct class names look at the gui or javadocs to see what options
are available and there full class name.